M4 Mac mini 16GB でローカルLLM を動かす — 具体的な選択肢と現実

はじめに
16GB の Mac mini でローカル LLM の動作を検証した。速くはないが実用範囲には乗るし、消費電力(負荷時で 30W 前後)まで含めて考えれば悪くない。
この記事は、M4 Mac mini base(16GB unified memory)でローカル LLM を動かすための、モデル選定・ランタイム選定・セットアップ手順と、実際に動かして踏んだ落とし穴の記録だ。後半の落とし穴 — Qwen3.5 系を Ollama で動かしたときの「応答が遅い・本文が帰ってこない」の正体 — がこの記事の本題になる。
1. 16GB という制約
16GB の unified memory で快適に動くのは、Q4 量子化で 7〜9B クラスまでだ。14B 超を Q4 で動かすと仮想メモリにスワップして 5 tok/s を割り込み、実用にならない。
そして本当の限界はモデルサイズだけではない。KV キャッシュとコンテキスト長がメモリを食う。モデル本体が載っても、長いコンテキストや裏で他のアプリが動いている状況だと、そこから先に破綻する。16GB は「モデルが載るか」ではなく「モデル + KV キャッシュ + OS + 作業アプリが同時に載るか」で考える必要がある。
2. Unified memory と NVIDIA GPU のアーキテクチャ差
比較対象として、手元の NVIDIA GeForce RTX 3060 12GB と並べてみる。
| 観点 | RTX 3060 12GB | M4 Mac mini 16GB |
|---|---|---|
| メモリ帯域 | 360 GB/s (GDDR6) | 120 GB/s (LPDDR5X) |
| 7-8B Q4 速度 | 約 38-45 tok/s | 約 20-35 tok/s |
| メモリ容量 | 専用 12GB(容量の壁が硬い) | unified 16GB(劣化が緩やか) |
| prefill | 強い(CUDA) | 弱い |
| 消費電力 | 170W 級 | 約 30W |
| エコシステム | CUDA(成熟) | MLX / Metal |
LLM のトークン生成はメモリ帯域律速なので、帯域が 3 倍ある NVIDIA GPU のほうが素の生成速度は速い。一方 Mac は容量が unified で融通が利き、消費電力が小さく静音で 24 時間稼働に向く。どちらが上という話ではなく、性質が違う。
3. モデル選定
daily driver は Qwen3.5-9B(Q4_K_M, 約 6.6GB, Ollama タグ qwen3.5:9b)。16GB に余裕で載り、256K コンテキスト・vision・tools・thinking 対応。
一点訂正しておくと、「Qwen3.6-9B」というモデルは存在しない。9B は Qwen3.5 系だ。Qwen3.6 ファミリーは dense 27B と 35B-A3B(MoE)のみ。MoE の A3B(active 3B)は「1 トークンあたり 3B だけ動く」という速度・演算量の話で、メモリには総量 35B 全部を載せる必要がある。ここを取り違えると「3B 相当だから 16GB で動く」と誤解する。
4. ランタイム選定
ローカル推論のスタックは 3 層で捉えると正確だ。
- GGML: C のテンソル演算ライブラリ(行列計算・メモリ管理・GPU カーネル)。土台。
- llama.cpp: GGML の上で推論そのもの(モデルロード、forward pass、サンプリング、GGUF、
llama-server)を実装。ほぼ全てのローカル推論ツールの中核。 - Ollama: llama.cpp の上に乗る運用ラッパー(
ollama pull、Modelfile、自動メモリ管理、OpenAI 互換 API)。
Ollama は一度 llama.cpp から離れて独自エンジンを試したが、2026 年 5 月に upstream の llama.cpp(llama-server)へ出戻った。今は「GGUF は llama.cpp、Apple Silicon の safetensors は MLX」の二本立てだ。
16GB では Ollama-GGUF が現実解になる。Ollama の MLX バックエンドは 32GB+ の unified memory 推奨で、16GB は対象外として llama.cpp に fallback するからだ。MLX 速度を本気で取りたいなら Ollama ではなく mlx-lm を直接使うことになるが、16GB の常時稼働サーバーなら素直に Ollama-GGUF でいい。
5. セットアップ
基本はこれだけだ。
ollama pull qwen3.5:9b
OLLAMA_HOST=0.0.0.0 ollama serve # LAN 内の他デバイスから叩けるよう公開
ここで一つ落とし穴がある。Homebrew の formula 版 ollama(0.30.x 系)は llama-server バイナリが同梱されておらず起動できない(GitHub issue #16535)。llama-server binary not found で止まる。公式ビルド(ollama.com の .dmg、または brew install --cask ollama-app)を使えば解決する。CLI はアプリ同梱の llama-server を参照する。
コンテキスト長は最初から欲張らず、8K〜16K で固定して始めるのが無難。常時稼働サーバーなら Modelfile で固定しておく。
cat > Modelfile <<'EOF'
FROM qwen3.5:9b
PARAMETER num_ctx 8192
PARAMETER temperature 0.3
EOF
ollama create qwen-dev -f Modelfile
モデルが実際に unified memory に載っているかは ollama ps で確認する。スワップに落ちると体感速度が死ぬので、ここは必ず見る。
6. 実測と落とし穴(本題)
ここからが本題。素の生成速度は 9B / M4 base で約 18 tok/s。これがこの構成の地力だ。
ところが最初、「こんにちは」程度の入力に 30〜60 秒かかり、しかも時々空の返答が返ってきた。原因を順に潰していった結果、真因は 3 つに整理できた。
真因① thinking(最重要)
Qwen3.5 は推論モデルで、think を明示しないとデフォルトで思考が ON になる。このとき出力は message.thinking フィールドに流れ、message.content は空のまま進む。そして思考が num_predict(生成トークン上限)を使い切ると、答えに到達する前に done_reason: length で打ち切られ、content が空のまま終わる。
実際に curl で叩くと、content が空で thinking だけが 256 トークン分埋まっていた。「空返答」の正体はこれだった。
直し方は think を false にする。ただし 2 点注意がある (Ollama issue #14793)。
thinkはoptionsの中ではなくトップレベルのパラメータとして渡す。- chat API で渡す(generate API は
think: falseを無視するバグがある)。
curl http://your-host:11434/api/chat -d '{
"model": "qwen3.5:9b",
"messages": [{"role": "user", "content": "あなたの知識カットオフの年月日を教えて。1文で簡潔に。"}],
"stream": false,
"think": false,
"options": {"presence_penalty": 0.0, "num_predict": 256}
}'
think: false にしたら、同じ質問が 16 トークン・6 秒・content にちゃんと答えが入って返ってきた。
ただ think の場合に比べて精度は大きく落ちる。ここはマシンスペックの限界があるので妥協するしかない。
真因② presence_penalty = 1.5
Ollama の qwen3.5 デフォルトの presence_penalty が 1.5 と高い。これは既出トークンを強く罰して新規性を促すパラメータで、1.5 は「話を締めずに新しいことを言い続ける」方向に効き、長文化の二次要因になる。0 に下げると応答が適切な長さで自然に終わる。
num_predict の設定上の注意
num_predict を 4096 にしていると、上記の暴走が起きたときに 4096 トークンをフルに生成し、18 tok/s では 3 分 48 秒かかる。失敗のたびにこの時間を待たされるのは消耗するので、512〜1024 に下げて被害を限定する。thinking を切れば正常な応答はずっと手前で終わるので、512 で十分だ。
誤診と訂正
最初はマルチターンで起きる空返答を「Qwen3.5 hybrid アーキテクチャのコンテキストキャッシュのバグ」だと疑っていた。だがレスポンスの JSON を見たら、真因は単純に thinking がトークン予算を食い尽くしていたことだった。「単発なら返るがマルチターンだと空」という挙動も、思考が予算内で終わるか溢れるかの差で全部説明がつく。手元で検証して結論を訂正した。
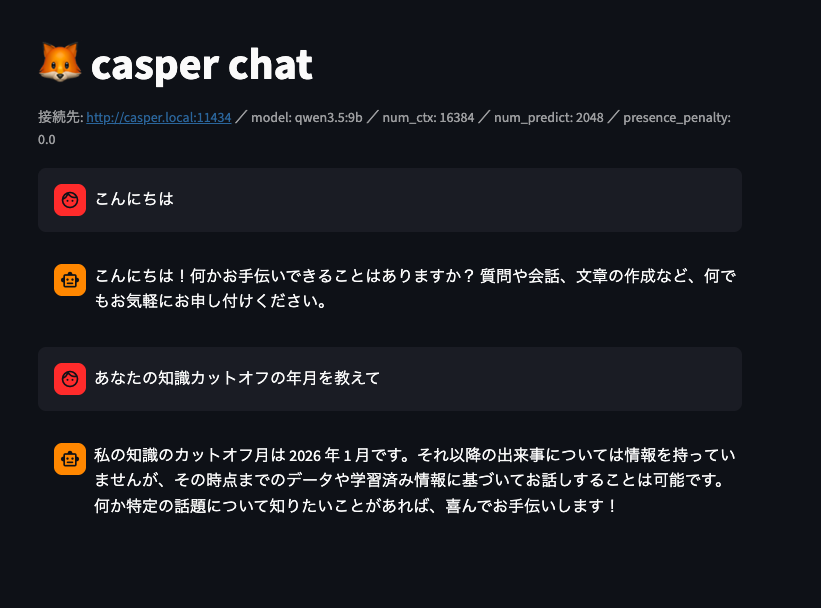
自己申告のカットオフは当てにならない
ついでに。モデルに「君の知識カットオフはいつ?」と聞くと「2026 年」などと返すが、これは信用できない。モデルは自分の学習データの最終日を取り出せる事実として保持しているわけではなく、それっぽい値を生成しているだけだ。ベンチマークの指標には使えない。
確定した設定
think: false
presence_penalty: 0.0
num_predict: 512
7. 接続用チャットアプリ
Mac mini 上の Ollama に LAN 経由で繋ぐ簡易チャットを、PEP 723 + uv の 1 ファイルで書いた。#!/usr/bin/env -S uv run --script のシェバンと inline script metadata で、依存(streamlit / ollama / watchdog)込みで 1 ファイル完結する。
(ちなみに casper は検証用 Mac mini の名前)
#!/usr/bin/env -S uv run --script
# /// script
# requires-python = ">=3.11"
# dependencies = [
# "streamlit>=1.43",
# "ollama",
# "watchdog",
# ]
# ///
"""
casper_chat_vision.py — casper の Ollama と通信する画像入力対応チャット(ポータブル1ファイル版)
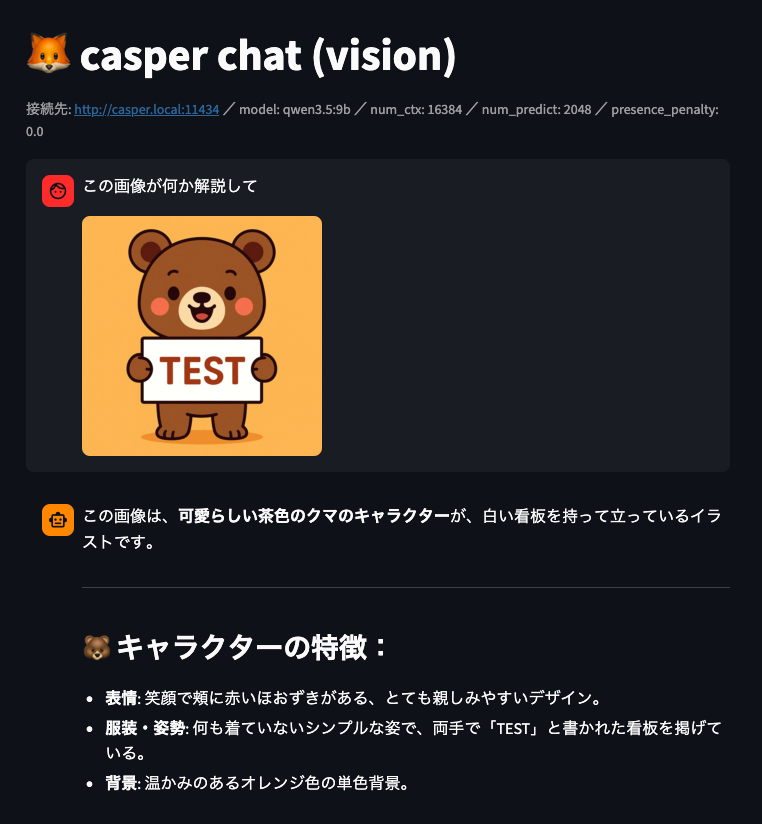
casper_chat.py に「画像添付」を足したもの。Qwen3.5-9B など vision 対応モデルに
画像を渡せる。チャット入力欄のクリップ(📎)から画像を添付して送る。
実行:
chmod +x casper_chat_vision.py
./casper_chat_vision.py
→ uv が依存を隔離環境に自動インストールし、ブラウザで起動
shebang が使えない環境では:
uv run --script casper_chat_vision.py
前提:
casper 側で Ollama が LAN 公開で起動していること
OLLAMA_HOST=0.0.0.0 ollama serve
vision 対応モデルが pull 済みであること(qwen3.5:9b は対応)
ollama pull qwen3.5:9b
注意:
- 画像添付は file_type の拡張子のみ。vision 非対応モデルに送るとエラーになる。
- 画像は会話履歴に積まれ、毎ターン再送(再 prefill)される。M4 は prefill が弱いので
大きい画像・複数画像・長い会話だと遅くなる。重い時は「会話をクリア」するか画像を縮小する。
"""
# pyright: reportMissingImports=false
import sys
def run_app() -> None:
"""Streamlit ランタイム上で動くアプリ本体。"""
import streamlit as st
from ollama import Client
# ---- デフォルト設定(サイドバーで上書き可)----
DEFAULT_HOST = "http://casper.local:11434"
DEFAULT_MODEL = "qwen3.5:9b"
IMAGE_TYPES = ["png", "jpg", "jpeg", "webp", "gif", "bmp"]
st.set_page_config(page_title="casper chat (vision)", page_icon="🦊")
st.title("🦊 casper chat (vision)")
with st.sidebar:
st.header("設定")
host = st.text_input("Ollama host", DEFAULT_HOST)
model = st.text_input("Model", DEFAULT_MODEL)
st.caption("画像を送るなら vision 対応モデル(例: qwen3.5:9b)にすること。")
num_ctx = st.selectbox(
"context window (num_ctx)",
[4096, 8192, 16384, 32768],
index=2, # 既定 16384
help="会話履歴+生成の合計上限。変更すると Ollama がモデルを再ロードする。"
"画像は多くのトークンを消費するので、画像を使うなら大きめが安全。",
)
unlimited = st.checkbox(
"出力上限なし (EOS まで, num_predict=-1)", value=False
)
num_predict_slider = st.slider(
"max tokens (num_predict)", 256, 8192, 2048, 256
)
num_predict = -1 if unlimited else num_predict_slider
temperature = st.slider("temperature", 0.0, 1.5, 0.3, 0.1)
# presence_penalty: qwen3.5 の Ollama 既定は 1.5 で、これが「だらだら長文化」の主因。
# 0 にすると応答が適切な長さで自然に終わる。繰り返しが気になれば 0.3 程度に上げる。
presence_penalty = st.slider(
"presence_penalty", 0.0, 1.5, 0.0, 0.1,
help="モデル既定の 1.5 が長文暴走の原因。0 で適切な長さに。繰り返すなら 0.3 程度。",
)
# thinking: ON だと思考が thinking フィールドに出て content が空になりやすい(#14793)。
# 既定 OFF = 直接 content に答えが出て速い。
think_enabled = st.checkbox(
"thinking を有効化(推論モデルの思考)", value=False,
help="OFF 推奨。ON だと思考に予算を使い遅くなる/空返答になりやすい。",
)
if st.button("会話をクリア", use_container_width=True):
st.session_state.messages = []
st.rerun()
np_label = "無制限(EOSまで)" if num_predict == -1 else str(num_predict)
st.caption(
f"接続先: {host} / model: {model} / num_ctx: {num_ctx} / "
f"num_predict: {np_label} / presence_penalty: {presence_penalty}"
)
client = Client(host=host)
# ---- 会話履歴(マルチターン保持)----
# 各 user メッセージは {"role","content","images"?} 形式。
# images は bytes のリスト(ollama-python が自動で base64 化する)。
if "messages" not in st.session_state:
st.session_state.messages = []
def render_message(m: dict) -> None:
"""履歴1件を表示。content と添付画像を出す。"""
with st.chat_message(m["role"]):
if m.get("content"):
st.markdown(m["content"])
for img in m.get("images", []):
st.image(img, width=240)
for m in st.session_state.messages:
render_message(m)
# ---- 入力(テキスト+画像添付)→ ストリーミング応答 ----
chat = st.chat_input(
"メッセージを入力(📎 から画像も添付可)",
accept_file="multiple",
file_type=IMAGE_TYPES,
)
if chat:
text = (chat.text or "").strip()
images = [f.getvalue() for f in (chat.files or [])]
if not text and not images:
st.stop() # 空送信は無視
user_msg = {"role": "user", "content": text}
if images:
user_msg["images"] = images
st.session_state.messages.append(user_msg)
render_message(user_msg)
with st.chat_message("assistant"):
thinking_box = None
if think_enabled:
thinking_box = st.expander("🧠 thinking", expanded=False).empty()
content_box = st.empty()
thinking_text = ""
content_text = ""
try:
# think は options ではなくトップレベルに渡す(Ollama chat API 仕様 / #14793)。
for chunk in client.chat(
model=model,
messages=st.session_state.messages,
stream=True,
think=think_enabled,
options={
"num_ctx": num_ctx,
"num_predict": num_predict,
"temperature": temperature,
"presence_penalty": presence_penalty,
},
):
msg = chunk["message"]
t = msg.get("thinking") or ""
c = msg.get("content") or ""
if t and thinking_box is not None:
thinking_text += t
thinking_box.markdown(thinking_text)
if c:
content_text += c
content_box.markdown(content_text)
except Exception as e:
content_text = (
f"⚠️ 通信エラー: {e}\n\n"
f"確認: ①casper で `OLLAMA_HOST=0.0.0.0 ollama serve` が起動しているか "
f"②host({host})と model({model})が正しいか "
f"③画像を送ったなら model が vision 対応か ④同一 LAN にいるか。"
)
content_box.markdown(content_text)
# thinking しか返らず content が空 = num_predict 不足で思考中に打ち切られた合図
if not content_text and thinking_text:
content_box.markdown(
"⚠️ 思考だけで終わって答えが出てない。"
"thinking を OFF にするか num_predict を上げてくれ。"
)
st.session_state.messages.append(
{"role": "assistant", "content": content_text}
)
def _running_under_streamlit() -> bool:
"""streamlit ランタイム上で実行されているかを判定する。"""
try:
from streamlit.runtime import exists
return exists()
except Exception:
return False
if __name__ == "__main__":
if _running_under_streamlit():
run_app()
else:
from streamlit.web import cli as stcli
sys.argv = ["streamlit", "run", __file__, "--server.headless=true"]
sys.exit(stcli.main())
ポイントは 3 つ。
- Streamlit は
streamlit runでしか起動できないので、streamlit.runtime.exists()で判定し、素の python で起動されたらstcli.main()で自分自身をstreamlit runで再起動するブートストラップを入れた。 - サイドバーで host / model / num_ctx / num_predict / temperature / presence_penalty と、thinking の ON/OFF トグルを操作できる。
thinkはトップレベルで渡す。 - thinking を ON にしたときは
message.thinkingを expander に、message.contentを本文に分けて表示する。content が空で thinking だけ返ってきたら「思考だけで終わっている」警告を出して、無言の空返答を防ぐ。
ストリーミング受信の核はこのあたり。
for chunk in client.chat(
model=model,
messages=st.session_state.messages,
stream=True,
think=think_enabled, # options ではなくトップレベル
options={
"num_ctx": num_ctx,
"num_predict": num_predict,
"temperature": temperature,
"presence_penalty": presence_penalty,
},
):
msg = chunk["message"]
t = msg.get("thinking") or ""
c = msg.get("content") or ""
if t and think_enabled:
thinking_text += t
thinking_box.markdown(thinking_text)
if c:
content_text += c
content_box.markdown(content_text)
PEP 723 + uv のポータブルスクリプトの書き方そのものは別記事に書いた。
画像認識もできる
8. まとめ
- 16GB の Mac mini は「軽作業なら yes、本気のエージェントなら no」。7〜9B の軽量タスクのオフロード先としては高 ROI だが、重いコーディングエージェントの常用には向かない。
- モデルは Qwen3.5-9B、ランタイムは Ollama-GGUF で十分。MLX を本気で取るなら mlx-lm 直。
- 重い推論は素直に NVIDIA の GPU(CUDA)を使ったほうがいい。帯域が効く。
- 一番実用的な学びは、qwen3.5 系の「遅い・空返答」は thinking + presence_penalty + num_predict の 3 点で説明できること。特に
think: falseはoptionsの外に置く。
開発相談をお待ちしています。